AI data annotation for localization
Turning human language judgments into structured data for AI

What AI data annotation is and why it matters for localization
AI data annotation is the process of adding meaning and context to language data so AI systems can learn how to handle it correctly. In localization, this means teaching AI how your organisation uses language, what is acceptable, what is risky, and what must stay consistent across markets.
A simple way to understand annotation is to look at the kinds of judgments humans make every day when reviewing content. A linguist or reviewer instantly recognises things like:
- This sentence is a product claim
- This clause is a limitation of liability
- This review is negative
- This image contains a cracked label
- This translation is acceptable
- This term must always be translated in a specific way
As humans, we recognise these patterns naturally. AI does not. Annotation is the way humans make these judgments explicit so AI systems can learn from them.
For localization, this is essential. Translation and multilingual content are full of hidden decisions about terminology, tone, legal meaning, cultural appropriateness and risk. Without annotation, AI systems treat everything as generic text. With annotation, they learn how language is actually used in your business.




What we do when we annotate data
AI data annotation always starts with clarity. We sit down with you and define the goal and the labels that matter for your organisation. These labels are the signals that tell AI what to look for and how to behave.
Examples of what we define together include:
- Detecting risky claims in marketing copy, such as claim types, prohibited claims, or compliance flags
- Identifying key fields in contracts, such as termination clauses, governing law, or liability caps
- Classifying customer support tickets by topic and urgency
- Marking preferred translations and forbidden terms for a specific domain
This step is crucial because it translates your internal knowledge into a structure that AI can understand and reuse consistently.

How the annotation process works in practice
Once the goals and labels are clear, the process follows a structured path.
First, relevant content is collected and prepared. This can include translated documents, source texts, contracts, marketing materials, support tickets, product documentation, or existing validated translations. Think of this as building a well organised library. Only the right books are selected, outdated or unreliable material is removed, and everything is sorted before anyone starts working with it.
Next, professional linguists carry out the core annotation work. This is where expertise really matters. Linguists label the data using the agreed rules, for example:
- Marking which translation is acceptable and which is not
- Tagging terminology that must always be used consistently
- Identifying legally sensitive clauses
- Flagging culturally inappropriate phrasing
An everyday analogy is coloured stickers in a document. One colour shows approved terminology, another highlights risk, and another indicates content that requires extra review. Over time, these signals form a clear system that AI can learn from.
After annotation, quality checks ensure consistency across languages, markets, and content types. Decisions are reviewed, aligned, and documented so they do not resurface later as repeated discussions or corrections.
Finally, annotated data is fed back into translation and content workflows. AI systems learn from these examples, and human reviewers validate the output to confirm that the system behaves as expected. Annotation is not a one time activity but a living asset that evolves as language, markets, and regulations change.
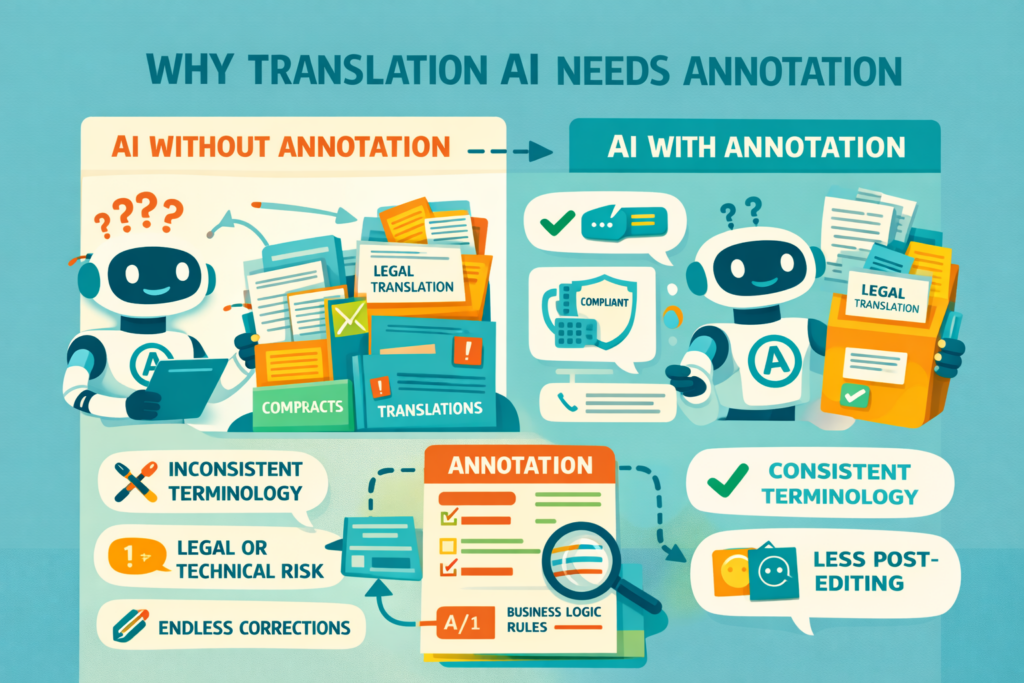
Why translation AI needs annotation to work well
When a company translates content, several invisible decisions are being made all the time:
- Which term is correct in this context?
- Is this phrase acceptable in this market?
- Is this wording legally safe?
- Does this sentence reflect our brand voice?
- Is this claim too strong, too weak, or misleading?
Humans do this instinctively. AI does not. With annotation, AI follows rules that reflect real business logic.
For businesses, this prevents:
- Inconsistent terminology across markets
- Legal or technical misinterpretations
- Endless post-editing corrections

How annotation improves translation and localization over time
When annotated data is consistently fed back into the system, clear improvements follow. Translation output becomes more consistent. Fewer corrections are needed. Human review becomes faster and more focused. Automation becomes safer rather than riskier.
In practice, this means:
- Lower post-editing effort
- Faster turnaround times
- Better quality at scale
- Less frustration for local markets
Instead of repeatedly fixing the same issues, teams move forward with confidence that decisions are remembered and applied.

Getting started with AI data annotation at Attached
Many organisations know their content could be more consistent and less risky but struggle to turn that knowledge into a system. That is where Attached comes in.
We help you identify where annotation adds the most value, define the right labels, apply expert linguistic judgment, and integrate annotation into your broader localization strategy. The result is not just better AI output today, but a foundation that improves quality, speed, and reliability over time.
If your organisation translates content at scale and wants AI that understands your language the way your people do, AI data annotation is the missing link. Partner with Attached to make that knowledge explicit, reusable, and future proof.






FAQs on AI data annotation
What is AI data annotation in simple terms?
AI data annotation is the process of adding meaning and context to text, images, or other data so AI systems can learn how to handle it correctly. In localization, it teaches AI how your organisation uses language, terminology, and tone.
Is AI data annotation only relevant for large companies?
No. It is most valuable once content volumes increase or when consistency, legal safety, or brand accuracy becomes important across markets. Mid sized organisations often benefit just as much as large enterprises.
What types of content can be annotated?
Common examples include marketing copy, legal documents, contracts, support tickets, product documentation, websites, and existing translations.
Does annotation improve machine translation quality?
Yes. Annotated data helps machine translation engines make better decisions about terminology, tone, and acceptability, which leads to more consistent output and less post editing.
Is annotation a one time project or an ongoing process?
It can start as a project, but the best results come from maintaining and expanding annotation as content, markets, and regulations evolve.

Why choose Attached
- Tailored solutions perfectly aligned with your specific needs and goals.
- A comprehensive service package to support your international growth and communication from A to Z.
- A dedicated team always ready to assist you, combining AI-powered tools with human expertise.